Test rewrite of the geometry assembler #320
Conversation
|
Some interesting results with a similar algorithm implemented in Julia (attempt 8): These benchmarks were done on Xeons. The difference from the previous set of benchmarks done on EPYCs is quite dramatic:
Attempt 8 is almost 2x faster than the others. Possible explanations:
|



|
Did another set of benchmarks on the offline cluster and got much more believable results: Attempts 4/6 are the fastest on this machine, and the Julia implementation is the slowest. And on the online cluster (where it really matters): Very similar results, all the C++ attempts are faster than the reference, and the Julia one is the slowest. These graphs are way more noisy than the ones from the offline cluster, I guess because there's some Karabo devices running on the same machine using some CPU. I think the benchmarks on the online cluster in addition to the massively simplified algorithm are a good enough reason to replace the current assembler, so I'm thinking I'll replace it with attempt 4. That's the simplest one, and from looking at the benchmarks I'd say there's no clear advantage to the more complicated ones. |






|
The point of the current implementation is to enable flexible and fast manipulation of the pixel (masking is a simple example of it) during assembling. As you already figure it out, assembling is just a copy and nothing is fancy. Also, the current implementation is not fully optimized as there was no requirement. There are also many other cases in EXtra-foam, which envision space for scaling up and including more complicated applications in the future. I would more than happy to see you if you could lead EXtra-foam to go in this direction :) |
Recently I've been playing around with re-implementing the geometry assembler, and I think it's at the point where we can figure out whether to go with it or not. It's not a clear decision because the results are... mixed. This PR is not meant to be merged, it's just for discussion.
TL;DR:
So this all started when I had an idea a while ago about using LUT's to assemble geometry, because from pulse to pulse you don't need to compute the output location for each pixel in the input, that only depends on the geometry so it can be computed just once and re-used. I went through about 6 iterations of this idea before finding one that I think works well enough to be considered, which is
assembleDetectorData6(). This is a micro-optimized version ofassembleDetectorData5(), which is close enough that I would suggest reading the code forassembleDetectorData5()to understandassembleDetectorData6(). In turn,assembleDetectorData5()is a slightly optimized version ofassembleDetectorData4(). The other attempts I think are not worth considering because they're either broken or too slow.Here's an overview of how it works:
generateAssemblyLUT2()(this requires a specific input array fromextra-geomto compute the LUT data). Let's define the number of pixels in a pulse as N, then the LUT is a 1D byte array of sizeN * 3. Each 3 bytes in the array are the first 3 bytes of a 4-byte int, and the idea is that since we can comfortably represent all possible LUT values (i.e. positions in the flattened output array) in 2^24 bits, we can cut the size of LUT by 25% by using 24-bit ints. This is to reduce the impact of the LUT on the CPU caches, the larger the LUT is the less space for the input and output arrays, and thus the more cache misses and worse performance.uint32is also slightly complicated so there's some comments about that here.Here are some graphs that I made from running this on Maxwell for pulse lengths from 1 - 800 pulses (the 'reference implementation' is the existing implementation):
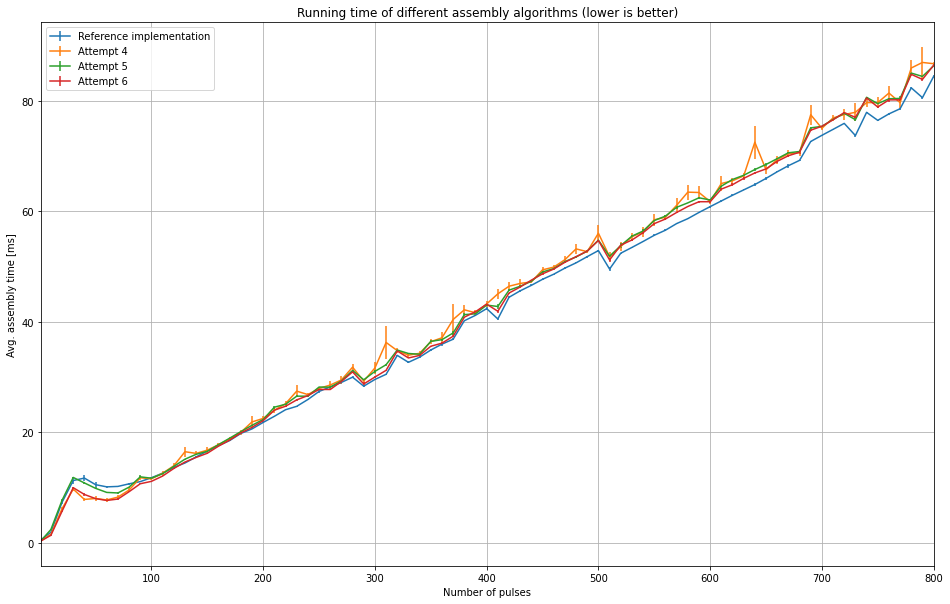
Interestingly, this outperforms the reference until ~150 pulses, after which it degrades. I would put this down to a quirk of the architecture of the machine rather than anything related to the algorithm because I did not see this while testing on my own machine. It would be interesting to see if this is the case on the online cluster nodes.
This shows that after the initial improvement up to ~150 pulses, performance degrades and then stabilizes at around ~97%-ish the performance of the existing implementation.
And in practice, this translates to a slowdown of about 2ms for 800 pulses. At 400 pulses it's around 1ms, so assuming a linear slowdown then I guess this would translate to 4ms at 1600 pulses (though at that point assembly itself would take ~160ms). It's interesting to me that the performance of
assembleDetectorData4()is so jittery, perhaps it's more sensitive to other workloads on the machine.General thoughts:
Thoughts? (anyone other than the reviewers, feel free to comment too :) )