diff --git a/README_zh.md b/README_zh.md
index 66044aca02..0f8fa606c3 100644
--- a/README_zh.md
+++ b/README_zh.md
@@ -11,7 +11,7 @@
@@ -46,7 +46,7 @@
***开始使用:***
- 查看我们已经实现的使用案例[在这里的文档中](https://docs.superduperdb.com/docs/category/use-cases),以及社区构建的应用,在专门的[superduper-community-apps仓库](https://github.com/SuperDuperDB/superduper-community-apps)中查看,并尝试在[浏览器中的Jupyter上](https://demo.superduperdb.com/)使用所有这些应用!
-想了解更多关于SuperDuperDB的信息,以及我们为什么认为它非常需要,请[阅读这篇博客文章](https://docs.superduperdb.com/blog/superduperdb-the-open-source-framework-for-bringing-ai-to-your-datastore/)。
+想了解更多关于SuperDuperDB的信息,以及我们为什么认为它非常需要,请[阅读这篇博客文章](https://blog.superduperdb.com/superduperdb-the-open-source-framework-for-bringing-ai-to-your-datastore/)。
---
diff --git a/docs/hr/blog/2023-09-08-introducing.md b/docs/hr/blog/2023-09-08-introducing.md
deleted file mode 100644
index 57e62d62ec..0000000000
--- a/docs/hr/blog/2023-09-08-introducing.md
+++ /dev/null
@@ -1,97 +0,0 @@
----
-slug: bringing-ai-to-your-datastore-in-python
-title: 'Introducing SuperDuperDB: Bringing AI to your Datastore in Python'
-authors: [blythed]
-tags: [AI, data-store, Python]
----
-
-It's 2023, and unless you've been in cryo-sleep since mid-2022, you'll have heard about the explosion of powerful AI and LLMs. Leveraging these LLMs, developers are now able to connect existing data with AI using vector search.
-
-
-
-AI models can allow users to extract valuable information out of their existing data stores (databases, data lakes, data warehouses), in a host of different ways: semantic search, retrieval augmented generation, visual classification, conditional image generation, recommendation systems, anomaly and fraud detection, image search, multimodal search, time-series analysis and much, much more.
-
-In the AI-powered future, a full-featured data application will have five parts:
-
-- Backend
-- Frontend
-- Data store
-- AI models
-- Vector search
-
-There are many different solutions for AI model computations and vector search separately, but some deep pitfalls appear when you put both together.
-
-### A model has no natural way to talk to a datastore
-
-The most flexible frameworks for building AI models, like PyTorch, don’t understand text or images out-of-the-box without writing custom code.
-
-Model libraries containing precompiled and trained AI models often support text but not computer vision or audio classification. Worse, you can’t just pass a data store connection to such a library, and tell the library to use the connection to train the model: you have to write more custom code.
-
-There is no general Python abstraction bringing self-built models like PyTorch, models imported from libraries like Scikit-Learn, and models hosted behind APIs like OpenAI, together under one roof with existing data stores: even more custom code.
-
-The result is that developers still must perform considerable coding to connect AI models with their data stores.
-
-### Vector databases mean data fragmentation and difficulties with data-lineage
-
-A vector database is powerful but leaves architects and developers with questions:
-
-- Should all data now live in the vector database?
-- Should the vector database only contain vectors?
-
-Ideally, data would stay in the primary datastore, but many datastores do not have a vector search implementation.
-
-On the other hand, it is problematic to make the vector database the primary datastore for an application, as most vector databases lack the specialized features of classical relational databases or document stores, and offer few consistency or performance guarantees.
-
-### Connect models and datastores with SuperDuperDB
-
-- SuperDuperDB is a framework which wraps data stores and AI models, with minimal boilerplate code.
-- Arbitrary models from open-source are applied directly to datastore queries and the outputs can be saved right back in the datastore, keeping everything in one location. Computations scale using the rich and diverse tools in the PyData ecosystem.
-- SuperDuperDB allows complex data types as inputs to AI models, such as images, audio and beyond.
-- SuperDuperDB can instantly make a classical database or data store vector-searchable. SuperDuperDB wraps well-known query APIs with additional commands for vector search, and takes care of organizing the results into a consistent result set for databases without a native vector-search implementation.
-- SuperDuperDB can use a query to train models directly on the data store. The fully open-source SuperDuperDB environment provides a scalable and serverless developer experience for model training.
-
-### Get started easily, and go far
-
-SuperDuperDB is designed to make it as simple as possible to get started. For example, to connect with SuperDuperDB using MongoDB and Python, just type:
-
-```python
-from superduperdb import superduper
-from pymongo import MongoClient
-
-db = MongoClient().my_database
-db = superduper(db)
-```
-
-At the same time, SuperDuperDB is ready for the full range of modern AI tools. It scales horizontally and includes a flexible approach allowing arbitrary AI frameworks to be used together, including torch, transformers, sklearn and openai.
-
-- GitHub: https://github.com/SuperDuperDB/superduperdb
-- Docs: https://docs.superduperdb.com
-- Blog: https://www.superduperdb.com/blog
-
-### The road ahead
-
-In the weeks and months to come we’ll be:
-
-- Adding SQL support (already close to completion)
-- Building bridges to more AI frameworks, libraries, models and API services
-- Creating tools to manage a SuperDuperDB deployment in production
-
-### Useful Links
-
-- **[Website](https://superduperdb.com/)**
-- **[GitHub](https://github.com/SuperDuperDB/superduperdb)**
-- **[Documentation](https://docs.superduperdb.com/docs/category/get-started)**
-- **[Blog](https://docs.superduperdb.com/blog)**
-- **[Example Use Cases & Apps](https://docs.superduperdb.com/docs/category/use-cases)**
-- **[Slack Community](https://join.slack.com/t/superduperdb/shared_invite/zt-1zuojj0k0-RjAYBs1TDsvEa7yaFGa6QA)**
-- **[LinkedIn](https://www.linkedin.com/company/superduperdb/)**
-- **[Twitter](https://twitter.com/superduperdb)**
-- **[Youtube](https://www.youtube.com/@superduperdb)**
-
-### Contributors are welcome!
-
-SuperDuperDB is open-source and permissively licensed under the [Apache 2.0 license](https://github.com/SuperDuperDB/superduperdb/blob/main/LICENSE). We would like to encourage developers interested in open-source development to contribute in our discussion forums, issue boards and by making their own pull requests. We'll see you on [GitHub](https://github.com/SuperDuperDB/superduperdb)!
-
-### Become a Design Partner!
-
-We are looking for visionary organizations which we can help to identify and implement transformative AI applications for their business and products. We're offering this absolutely for free. If you would like to learn more about this opportunity please reach out to us via email: partnerships@superduperdb.com
\ No newline at end of file
diff --git a/docs/hr/blog/2023-09-09-vector-search.mdx b/docs/hr/blog/2023-09-09-vector-search.mdx
deleted file mode 100644
index 2109462f67..0000000000
--- a/docs/hr/blog/2023-09-09-vector-search.mdx
+++ /dev/null
@@ -1,217 +0,0 @@
----
-slug: introduce-vector-search-to-your-favourite-database-with-superduperdb
-title: Enable Vector Search in MongoDB with SuperDuperDB
-authors: [blythed]
-tags: [AI, vector-search]
----
-
-_In this blog-post we show you how to easily operate vector-search in MongoDB
-Atlas using SuperDuperDB, leading to many savings and efficiencies in
-your AI development._
-
----
-
-In 2023 vector-databases are hugely popular; they provide the opportunity for developers to connect LLMs, such as OpenAI’s GPT models, with their data, as well as providing the key to deploying “search-by-meaning” on troves of documents.
-
-
-
-However: a key unanswered question, for which there is no widely accepted answer, is:
-
-:::info
-How do the vectors in my vector-database get there in the first place?
-:::
-
-Vectors (arrays of numbers used in vector-search) differ from the content of most databases, since they need to be calculated on the basis of other data.
-
-Currently there are 2 approaches:
-
-## Possibility 1: models live together with the database to create vectors at insertion time
-
-When data is inserted into a vector-database, the database may be configured to “calculate” or “compute” vectors on the basis of this data (generally text). This means that the database environment also has access to some compute and AI models, or access to APIs such as OpenAI, in order to obtain vectors.
-
-Examples of this approach are:
-
-- _Weaviate_ (support for a range of pre-defined models, some support for bringing own model)
-- _Chroma_ (support for OpenAI and sentence_transformers)
-
-**Pros**:
-
-- The data and compute live together, so developers don’t need to create an additional app in order to use the vector-database
-
-**Cons**:
-
-- Developers are limited by the models available in the vector-database and the compute resources on the vector-database server
-- Primary data needs to be stored in the vector-database; classic-database + external vector-search isn’t an expected pattern.
-- Training of models is generally not supported.
-
-## Possibility 2: the vector-database requires developers to provide their own vectors with their own models
-
-In this approach, developers are required to build an app which deploys model computations over data which is extracted from the datastore.
-
-Examples of this approach are:
-
-- _LanceDB_
-- _Milvus_
-
-**Pros**:
-
-- By developing a vector-computation app, the user can use the full flexibility of the open-source landscape for computing these vectors, and can architect compute resources independently from vector-database resources
-- The vector-database “specializes” in vector-search and storage of vectors, giving better performance guarantees as a result
-
-**Cons**:
-
-- Huge overhead of building one’s own computation app.
-- All communication between app, vector-database and datastore (if using external datastore) must be managed by the developer
-
-### Enter SuperDuperDB
-
-:::info
-SuperDuperDB is a middle path to scalability, flexiblity and ease-of-use in vector-search and far beyond.
-:::
-
-- SuperDuperDB is an open-source Python environment which wraps databases and AI models with additional functionality to make them “ready” to interface with one-another; developers are able to host their data in a “classical” database, but use this database as a vector-database.
-- SuperDuperDB allows users to integrate any model from the Python open source ecosystem (torch, sklearn, transformers, sentence_transformers as well as OpenAI’s API), with their datastore. It uses a flexible scheme, allowing new frameworks and code-bases to be integrated without requiring the developer to add additional classes or functionality.
-- SuperDuperDB can be co-located with the database in infrastructure, but at the same time has access to its own compute, which is scalable. This makes it vertically performant and at the same time, ready to scale horizontally to accommodate larger usage.
-- SuperDuperDB enables training directly with the datastore: developers are only required to specify a database-query to initiate training on scalable compute.
-- Developers are not required to program tricky boilerplate code or architectures for computing vector outputs and storing these back in the database. This is all supported natively by SuperDuperDB.
-- SuperDuperDB supports data of arbitrary type: with its flexible serialization model, SuperDuperDB can handle text, images, tensors, audio and beyond.
-- SuperDuperDB’s scope goes far beyond vector-search; it supports models with arbitrary outputs: classification, generative AI, fore-casting and much more are all within scope and supported. This allows users to build interdependent models, where base models feed their outputs into downstream models; this enables transfer learning, and quality assurance via classification on generated outputs, to name but 2 key outcomes of SuperDuperDB’s integration model.
-
-### Minimal boilerplate to connect to SuperDuperDB
-
-Connecting to MongoDB with SuperDuperDB is super easy. The connection may be used to insert documents, although insertion/ ingestion can also proceed via other sources/ client libraries.
-
-```python
-import json
-import pymongo
-
-from superduperdb import superduper
-from superduperdb.container.document import Document
-from superduperdb.db.mongodb.query import Collection
-
-db = pymongo.MongoClient().documents
-db = superduper(db)
-
-collection = Collection('wikipedia')
-
-with open('wikipedia.json') as f:
- data = json.load(f)
-
-db.execute(
- collection.insert_many([Document(r) for r in data])
-)
-```
-
-### Set up vector-search with SuperDuperDB in one command!
-
-import Tabs from '@theme/Tabs';
-import TabItem from '@theme/TabItem';
-
-```mdx-code-block
-
-
-```
-
-```python
-from superduperdb.container.vector_index import VectorIndex
-from superduperdb.container.listener import Listener
-from superduperdb.ext.numpy.array import array
-from superduperdb.ext.openai import OpenAIEmbedding
-
-db.add(
- VectorIndex(
- identifier=f'wiki-index-openai',
- indexing_listener=Listener(
- model=OpenAIEmbedding(model='text-embedding-ada-002'),
- key='abstract',
- select=collection.find(),
- predict_kwargs={'max_chunk_size': 1000},
- )
- )
-)
-```
-
-```mdx-code-block
-
-
-```
-
-```python
-from superduperdb.container.vector_index import VectorIndex
-from superduperdb.container.listener import Listener
-from superduperdb.ext.numpy.array import array
-from sentence_transformers import Pipeline
-
-model = Model(
- identifier='all-MiniLM-L6-v2',
- object=sentence_transformers.SentenceTransformer('all-MiniLM-L6-v2'),
- encoder=array('float32', shape=(384,)),
- predict_method='encode',
- batch_predict=True,
-)
-
-db.add(
- VectorIndex(
- identifier=f'wiki-index-sentence-transformers',
- indexing_listener=Listener(
- model=model,
- key='abstract',
- select=collection.find(),
- predict_kwargs={'max_chunk_size': 1000},
- )
- )
-)
-```
-
-```mdx-code-block
-
-
-```
-
-This approach is simple enough to allow models from a vast range of libraries and sources to be implemented: open/ closed source, self-built or library based and much more.
-
-Now that the index has been created, queries may be dispatched in a new session to SuperDuperDB without reloading the model:
-
-```python
-cur = db.execute(
- collection
- .like({'title': 'articles about sport'}, n=10, vector_index=f'wiki-index')
- .find({}, {'title': 1})
-)
-
-for r in cur:
- print(r)
-```
-
-The great thing about using MongoDB or a similar battle tested database for vector-search, is that it can be easily combined with important filtering approaches. In this query, we restrict the results to a hard match involving the word “Australia”:
-
-```python
-cur = db.execute(
- collection
- .like({'title': 'articles about sport'}, n=100, vector_index=f'wiki-index-{model.identifier}')
- .find({'title': {'$regex': '.*Australia'}})
-)
-
-for r in cur:
- print(r['title'])
-```
-
-### Useful Links
-
-- **[Website](https://superduperdb.com/)**
-- **[GitHub](https://github.com/SuperDuperDB/superduperdb)**
-- **[Documentation](https://docs.superduperdb.com/docs/category/get-started)**
-- **[Blog](https://docs.superduperdb.com/blog)**
-- **[Example Use Cases & Apps](https://docs.superduperdb.com/docs/category/use-cases)**
-- **[Slack Community](https://join.slack.com/t/superduperdb/shared_invite/zt-1zuojj0k0-RjAYBs1TDsvEa7yaFGa6QA)**
-- **[LinkedIn](https://www.linkedin.com/company/superduperdb/)**
-- **[Twitter](https://twitter.com/superduperdb)**
-- **[Youtube](https://www.youtube.com/@superduperdb)**
-
-### Contributors are welcome!
-
-SuperDuperDB is open-source and permissively licensed under the [Apache 2.0 license](https://github.com/SuperDuperDB/superduperdb/blob/main/LICENSE). We would like to encourage developers interested in open-source development to contribute in our discussion forums, issue boards and by making their own pull requests. We'll see you on [GitHub](https://github.com/SuperDuperDB/superduperdb)!
-
-### Become a Design Partner!
-
-We are looking for visionary organizations which we can help to identify and implement transformative AI applications for their business and products. We're offering this absolutely for free. If you would like to learn more about this opportunity please reach out to us via email: partnerships@superduperdb.com
diff --git a/docs/hr/blog/2023-09-12-rag-question-answering.mdx b/docs/hr/blog/2023-09-12-rag-question-answering.mdx
deleted file mode 100644
index c1049763c5..0000000000
--- a/docs/hr/blog/2023-09-12-rag-question-answering.mdx
+++ /dev/null
@@ -1,182 +0,0 @@
----
-slug: building-a-documentation-chatbot-using-fastapi-react-mongodb-and-superduperdb
-title: Building a Documentation Chatbot using FastAPI, React, MongoDB and SuperDuperDB
-authors: [nenb]
-tags: [RAG, vector-search]
----
-
-_Imagine effortlessly infusing AI into your data repositories—databases, data warehouses, or data lakes—without breaking a sweat. With SuperDuperDB, we aim to make this dream a reality.
-We want to provide everyone with the tools to build AI applications directly on top of their data stores,
-with just a pinch of Python magic sprinkled on top!_ 🐍✨
-
-_In this latest blog post we take a dive into one such example - a Retrieval Augmented Generation (RAG) app we built directly on top of our MongoDB store._
-
-
-
----
-
-import Bot from './rag-question-answering-components/Bot';
-
-Since we’re in the business of building open-source software, a logical in-house application of our own technology is a question-answering app, directly on our own documentation. We built this app using SuperDuperDB together with FastAPI, React and MongoDB (the “FARMS” stack).
-
-We use retrieval augmented generation, or RAG, to integrate an existing Large Language Model (LLM) with our own data; including documents found in vector-search in an initial pass, enables using an LLM on a domain it was not trained on. SuperDuperDB allows developers to apply RAG to their own standard database, instead of insisting that users migrate a portion of their data to a vector-search database such as Pinecone, Chroma or Milvus.
-
-Although SuperDuperDB’s functionality is more general than simply RAG and vector search, if a model’s output does indeed consist of vectors, it’s dead easy with SuperDuperDB to use these vectors downstream in vector search and RAG applications. We’ll post more about the range of possibilities with SuperDuperDB in the coming weeks.
-
-** 🤖 Let's ask the chatbot to tell us more about SuperDuperDB.**
-
-
-
-### Choosing our stack
-
-Right out of the box, SuperDuperDB supports MongoDB, a popular NoSQL database among full-stack developers. MongoDB's cloud service also provides a generous free-tier offering, and and we chose this for our storage.
-
-** 🚧 SuperDuperDB has experimental support for SQL databases which will be greatly expanded in the coming weeks and months!**
-
-We chose FastAPI for the web framework because it creates a self-documenting server, it’s extremely full-featured, and has a large community of users - and yes, because it’s trendy. The FARM stack combines both MongoDB and FastAPI, and so it seemed natural to build our RAG app by adding SuperDuperDB to FARM to make FARMS!
-
-### Setting up the code
-
-We decided to stick fairly closely to a typical FastAPI directory structure, the major difference being that we now have a new `ai/` subdirectory that contains two new modules: `artifacts.py` and `components.py`.
-
-```
-backend
-|___ ai
-| |___ __init__.py
-│ |___ artifacts.py
-| |___ components.py
-│ |___ utils # AI helper functions here
-│ |__ ...
-|___ documents # Our REST backend has a single 'documents' route
-| |___ __init__.py
-| |___ models.py # Pydantic models here
-| |___ routes.py # AI-enhanced CRUD logic here
-|___ __init__.py
-|___ app.py
-|___ config.py
-|___ main.py
-```
-
-### Artifacts
-
-** 🤖 Let's Question The Docs to learn more about Artifacts.**
-
-
-
-To build a program, you first must understand its data, and a RAG app is no different. Here, our data source are Markdown files, and we want to process them in a way which is most suitable for answering the questions we would like the LLM to answer. Here there's a trade-off: splitting the text into too large chunks, makes it harder to get good specificity in the vector-search step of RAG. However, splitting the docs into larger chunks, allows the LLM to use coherently ordered text to contextualize the answer it formulates.
-
-SuperDuperDB supports a wide range of models for prediction and training, and flexible serialization: for instance, we might use `spacy` for pre-processing labels, `torchvision` for vectorizing images and `transformers` for multi-modal retrieval. (But the program is not dependent on all these models! “Don’t pay for what you don’t use” is our motto.)
-
-Once we have our artifacts, `superduperdb` takes care of the rest. All serialization, creation and tracking of metadata, and job orchestration is handled automatically: the ultimate goal is to make the development of AI applications possible for anyone. For our RAG app, this step looks roughly like the following:
-
-```python
-from superduperdb.container.document import Document
-from superduperdb.db.mongodb.query import Collection
-...
-
-# `artifacts` are chunked Markdown files
-documents = [Document({"KEY": v}) for v in artifacts]
-db.execute(Collection(name="NAME").insert_many(documents))
-```
-
-### Components
-
-** 🤖 QtD again!**
-
-
-
-We are only going to use that first feature, and install our AI models inside our database.
-
-** 💡 But Components can also listen for specific events before performing an action, track statistics of database artifacts over time and even train models.**
-
-We chose `text-embedding-ada-002` for our text embedding model, which we compute on the app's own server. For the chatbot, we selected the well-known `gpt-3.5-turbo`; now we can start talking to our chatbot!
-
-### Querying the database
-
-Our app is a particularly simple example of a CRUD app without the UPDATE or DELETE actions: once we have created our artifacts, we just have to READ the database for the text most similar to our question.
-
-### Building queries
-
-Using SuperDuperDB to build a query to search for relevant text snippets is very similar to using a standard MongoDB driver such as `pymongo`, but with additional keyword arguments like n in this example, which says how many similar items to return from the database.
-
-```python
-from superduperdb.db.mongodb.query import Collection
-
-context = (
- Collection(name="NAME")
- .like(
- {"KEY": query}, # Example: 'What is SuperDuperDB?'
- n=5,
- vector_index="NAME2",
- )
- .find()
-)
-```
-
-### Dispatching QA queries
-
-Under the hood, SuperDuperDB can be configured to perform searches and comparisons using a vector database like the open-source LanceDB, or MongoDB Atlas, which is what we used in QtD.
-
-Executing a query is also very similar to a standard CRUD application, except that the database needs to be wrapped in a SuperDuperDB after it is created:
-
-```python
-from pymongo import MongoClient
-
-from superduperdb import superduper
-
-MONGO_URI = ...
-
-mongo_db = MongoClient(MONGO_URI)
-db = superduper(mongo_db) # It's now a super duper database!
-
-db.execute(context) # proceed as normal
-```
-
-### Summary
-
-The FARM stack works well with SuperDuperDB in Python to build RAG applications.
-
-SuperDuperDB’s support for vector search allows developers to minimize the problems with LLM hallucinations, as well as extending LLM coverage to domains the LLM was not trained on.
-
-Many RAG and question-answering applications use `langchain`, but SuperDuperDB stands out with its lightweight third-party integrations, support for “bring your own model”, and greater scope, incorporating scalable inference and training directly in your database.
-
-### SuperDuperDB into the future!
-
-** 🤖 Let's see if the bot can help us decide what to do next.**
-
-
-
-Thanks for reading! If you have any questions about this article, or SuperDuperDB in general, please don’t hesitate to contact us at opensource@superduperdb.com.
-
-### Useful Links
-
-- **[Question the docs online](https://www.qtd.superduperdb.com/)!**
-- **[Website](https://superduperdb.com/)**
-- **[GitHub](https://github.com/SuperDuperDB/superduperdb)**
-- **[Documentation](https://docs.superduperdb.com/docs/category/get-started)**
-- **[Blog](https://docs.superduperdb.com/blog)**
-- **[Example Use Cases & Apps](https://docs.superduperdb.com/docs/category/use-cases)**
-- **[Slack Community](https://join.slack.com/t/superduperdb/shared_invite/zt-1zuojj0k0-RjAYBs1TDsvEa7yaFGa6QA)**
-- **[LinkedIn](https://www.linkedin.com/company/superduperdb/)**
-- **[Twitter](https://twitter.com/superduperdb)**
-- **[Youtube](https://www.youtube.com/@superduperdb)**
-
-### Contributors are welcome!
-
-SuperDuperDB is open-source and permissively licensed under the [Apache 2.0 license](https://github.com/SuperDuperDB/superduperdb/blob/main/LICENSE). We would like to encourage developers interested in open-source development to contribute in our discussion forums, issue boards and by making their own pull requests. We'll see you on [GitHub](https://github.com/SuperDuperDB/superduperdb)!
-
-### Become a Design Partner!
-
-We are looking for visionary organizations which we can help to identify and implement transformative AI applications for their business and products. We're offering this absolutely for free. If you would like to learn more about this opportunity please reach out to us via email: partnerships@superduperdb.com
diff --git a/docs/hr/blog/2023-09-29-superduperdb-now-supports-cohere-and-anthropic-apis.md b/docs/hr/blog/2023-09-29-superduperdb-now-supports-cohere-and-anthropic-apis.md
deleted file mode 100644
index 7b92f439a8..0000000000
--- a/docs/hr/blog/2023-09-29-superduperdb-now-supports-cohere-and-anthropic-apis.md
+++ /dev/null
@@ -1,77 +0,0 @@
-# SuperDuperDB now supports Cohere and Anthropic APIs
-
-*We're happy to announce the integration of two more AI APIs, Cohere and Anthropic, into SuperDuperDB.*
-
----
-
-[Cohere](https://cohere.com/) and [Anthropic](https://www.anthropic.com/) provides AI developers with sorely needed alternatives to OpenAI for key AI tasks,
-including:
-
-- text-embeddings as a service
-- chat-completions as as service.
-
-
-
-## How to use the new integrations with your data
-
-We've posted some extensive content on how to use [OpenAI or Sentence-Transformers for encoding text as vectors](https://docs.superduperdb.com/docs/use_cases/items/compare_vector_search_solutions)
-in your MongoDB datastore, and also [how to question-your your docs hosted in MongoDB](https://docs.superduperdb.com/blog/building-a-documentation-chatbot-using-fastapi-react-mongodb-and-superduperdb).
-
-Now developers can easily use Cohere and Anthropic and drop in-replacements for the OpenAI models:
-
-For **embedding text as vectors** with OpenAI developers can continue to import the functionality like this:
-
-```python
-from superduperdb.ext.openai.model import OpenAIEmbedding
-
-model = OpenAIEmbedding(model='text-embedding-ada-002')
-```
-
-Now developers can **also** import Cohere's embedding functionality:
-
-```python
-from superduperdb.ext.cohere.model import CohereEmbedding
-
-model = CohereEmbedding()
-```
-
-Similarly, for **chat-completion**, can continue to use OpenAI like this:
-
-```python
-from superduperdb.ext.openai.model import OpenAIChatCompletion
-
-chat = OpenAIChatCompletion(
- prompt='Answer the following question clearly, concisely and accurately',
- model='gpt-3.5-turbo',
-)
-```
-
-Now developers can **also** import Anthropic's embedding functionality:
-
-```python
-from superduperdb.ext.anthropic.model import AnthropicCompletions
-
-chat = AnthropicCompletions(
- prompt='Answer the following question clearly, concisely and accurately',
-)
-```
-
-### Useful Links
-
-- **[Website](https://superduperdb.com/)**
-- **[GitHub](https://github.com/SuperDuperDB/superduperdb)**
-- **[Documentation](https://docs.superduperdb.com/docs/category/get-started)**
-- **[Blog](https://docs.superduperdb.com/blog)**
-- **[Example Use Cases & Apps](https://docs.superduperdb.com/docs/category/use-cases)**
-- **[Slack Community](https://join.slack.com/t/superduperdb/shared_invite/zt-1zuojj0k0-RjAYBs1TDsvEa7yaFGa6QA)**
-- **[LinkedIn](https://www.linkedin.com/company/superduperdb/)**
-- **[Twitter](https://twitter.com/superduperdb)**
-- **[Youtube](https://www.youtube.com/@superduperdb)**
-
-### Contributors are welcome!
-
-SuperDuperDB is open-source and permissively licensed under the [Apache 2.0 license](https://github.com/SuperDuperDB/superduperdb/blob/main/LICENSE). We would like to encourage developers interested in open-source development to contribute in our discussion forums, issue boards and by making their own pull requests. We'll see you on [GitHub](https://github.com/SuperDuperDB/superduperdb)!
-
-### Become a Design Partner!
-
-We are looking for visionary organizations which we can help to identify and implement transformative AI applications for their business and products. We're offering this absolutely for free. If you would like to learn more about this opportunity please reach out to us via email: partnerships@superduperdb.com
\ No newline at end of file
diff --git a/docs/hr/blog/2023-09-30-jump-start-ai-development.md b/docs/hr/blog/2023-09-30-jump-start-ai-development.md
deleted file mode 100644
index 81b547c93c..0000000000
--- a/docs/hr/blog/2023-09-30-jump-start-ai-development.md
+++ /dev/null
@@ -1,82 +0,0 @@
-# Jumpstart AI development on MongoDB with SuperDuperDB
-
-MongoDB now supports vector-search on Atlas enabling developers to build next-gen AI applications directly on their favourite database. SuperDuperDB now make this process painless by allowing to integrate, train and manage any AI models and APIs directly with your database with simple Python.
-
-Build next-gen AI applications - without the need of complex MLOps pipelines and infrastructure nor data duplication and migration to specialized vector databases:
-
-- **(RAG) chat applications** on documents hosted in MongoDB Atlas
-- **semantic-text-search & similiarity-search,** using vector embeddings of your data stored in Atlas
-- **image similarity & image-search** on images hosted in or referred to on MongoDB Atlas
-- **video search** including search *within* videos for key content
-- **content based recommendation** based on content hosted in MongoDB Atlas
-- **...and much, much more!**
-
-
-
-## Using SuperDuperDB to get started with Atlas vector-search
-
-There is great content on the MongoDB website on how to [get started with vector-search on Atlas](https://www.mongodb.com/library/vector-search/building-generative-ai-applications-using-mongodb). You'll see that there are several steps involved:
-
-1. Preparing documents for vector-search
-2. Converting text into vectors with an AI "model" and storing these vectors in MongoDB
-3. Setting up a vector-search index on Atlas vector-search
-4. Preparing a production API endpoint to convert searches in real time to vectors
-
-Each of these steps contains several sub-steps, and can become quite a headache for developers wanting to get started with vector-search.
-
-With SuperDuperDB, this preparation process can be boiled down to one simple command:
-
-```python
-from superduperdb.ext.openai.model import OpenAIEmbedding
-from superduperdb.container.vector_index import VectorIndex
-from superduperdb.container.listener import Listener
-from superduperdb.db.mongodb.query import Collection
-
-db.add(
- VectorIndex(
- identifier='my-index',
- indexing_listener=Listener(
- model=OpenAIEmbedding(model='text-embedding-ada-002'),
- key='key', # path of documents
- select=Collection('documents').find(),
- predict_kwargs={'max_chunk_size': 1000},
- ),
- )
-)
-```
-
-Under the hood SuperDuperDB does these things:
-
-1. Sets up an Atlas vector-search index in the `"documents"` collection
-2. Converts all documents into vectors
-3. Creates a function allow users to directly search using vectors, without needing to handle the conversion to vectors themselves: `Collection('documents').like({'key': 'This is the text to search with'}).find()`. This function can easily be served using, for example, FastAPI. (See [here](https://docs.superduperdb.com/blog/building-a-documentation-chatbot-using-fastapi-react-mongodb-and-superduperdb) for an example.)
-
-## Take AI even further with SuperDuperDB on MongoDB
-
-AI is not just vector-search over text-documents -- there are countless additional ways in which AI can be leveraged with data. This is where SuperDuperDB excels and other solutions come up short in leveraging data in MongoDB.
-
-SuperDuperDB also allows developers to:
-
-- Search the content of [images](https://docs.superduperdb.com/docs/use_cases/items/multimodal_image_search_clip), videos and [voice memos](https://docs.superduperdb.com/docs/use_cases/items/voice_memos) in MongoDB
-- Create [talk-to-your documents style chat applications](https://docs.superduperdb.com/blog/building-a-documentation-chatbot-using-fastapi-react-mongodb-and-superduperdb).
-- Use classical machine learning models [together with state-of-the-art computer vision models](https://docs.superduperdb.com/docs/use_cases/items/resnet_features).
-
-### Useful Links
-
-- **[Website](https://superduperdb.com/)**
-- **[GitHub](https://github.com/SuperDuperDB/superduperdb)**
-- **[Documentation](https://docs.superduperdb.com/docs/category/get-started)**
-- **[Blog](https://docs.superduperdb.com/blog)**
-- **[Example Use Cases & Apps](https://docs.superduperdb.com/docs/category/use-cases)**
-- **[Slack Community](https://join.slack.com/t/superduperdb/shared_invite/zt-1zuojj0k0-RjAYBs1TDsvEa7yaFGa6QA)**
-- **[LinkedIn](https://www.linkedin.com/company/superduperdb/)**
-- **[Twitter](https://twitter.com/superduperdb)**
-- **[Youtube](https://www.youtube.com/@superduperdb)**
-
-### Contributors are welcome!
-
-SuperDuperDB is open-source and permissively licensed under the [Apache 2.0 license](https://github.com/SuperDuperDB/superduperdb/blob/main/LICENSE). We would like to encourage developers interested in open-source development to contribute in our discussion forums, issue boards and by making their own pull requests. We'll see you on [GitHub](https://github.com/SuperDuperDB/superduperdb)!
-
-### Become a Design Partner!
-
-We are looking for visionary organizations which we can help to identify and implement transformative AI applications for their business and products. We're offering this absolutely for free. If you would like to learn more about this opportunity please reach out to us via email: partnerships@superduperdb.com
diff --git a/docs/hr/blog/2023-09-31-a-walkthrough-of-vector-search-on-mongodb-atlas-with-superduperdb/atlas_screen.png b/docs/hr/blog/2023-09-31-a-walkthrough-of-vector-search-on-mongodb-atlas-with-superduperdb/atlas_screen.png
deleted file mode 100644
index 8dc192c4d3..0000000000
Binary files a/docs/hr/blog/2023-09-31-a-walkthrough-of-vector-search-on-mongodb-atlas-with-superduperdb/atlas_screen.png and /dev/null differ
diff --git a/docs/hr/blog/2023-09-31-a-walkthrough-of-vector-search-on-mongodb-atlas-with-superduperdb/content.md b/docs/hr/blog/2023-09-31-a-walkthrough-of-vector-search-on-mongodb-atlas-with-superduperdb/content.md
deleted file mode 100644
index 8986e02ea4..0000000000
--- a/docs/hr/blog/2023-09-31-a-walkthrough-of-vector-search-on-mongodb-atlas-with-superduperdb/content.md
+++ /dev/null
@@ -1,187 +0,0 @@
-# Walkthrough: How to enable and manage MongoDB Atlas Vector Search with SuperDuperDB
-
-*In step-by-step tutorial we will show how to leverage MongoDB Atlas Vector Search
-with SuperDuperDB, including the generation of vector embeddings. Learn how to connect embedding APIs such as OpenAI or use embedding models for example from HuggingFace with MongoDB Atlas with simple Python commands.*
-
-:::info
-SuperDuperDB makes it very easy to set up multimodal vector search with different file types (text, image, audio, video, and more).
-:::
-
-
-
-**Install `superduperdb` Python package**
-
-Using vector-search with SuperDuperDB on MongoDB requires only one simple python package install:
-
-
-
-```bash
-pip install superduperdb
-```
-
-With this install SuperDuperDB includes all the packages needed to define a range of API based and package based
-vector-search models, such as OpenAI and Hugging-Face's `transformers`.
-
-**Connect to your Atlas cluster using SuperDuperDB**
-
-SuperDuperDB ships with it's own MongoDB python client, which supports
-all commands supported by `pymongo`. In the example below
-the key to connecting to your Atlas cluster is the `db` object.
-
-The `db` object contains all functionality needed to read and write to
-the MongoDB instance and also to define, save and apply a flexible range
-of AI models for vector-search.
-
-```python
-from superduperdb.db.base.build import build_datalayer
-from superduperdb import CFG
-import os
-
-ATLAS_URI = "mongodb+srv://
@/"
-OPENAI_API_KEY = ""
-
-os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
-
-CFG.data_backend = ATLAS_URI
-CFG.vector_search = ATLAS_URI
-
-db = build_datalayer()
-```
-
-**Load your data**
-
-You can download some data to play with from [this link](https://superduperdb-public.s3.eu-west-1.amazonaws.com/pymongo.json):
-
-```bash
-curl -O https://superduperdb-public.s3.eu-west-1.amazonaws.com/pymongo.json
-```
-
-The data contains all inline doc-strings of the `pymongo` Python API (official
-MongoDB driver for Python). The name of the function or class is in `"res"` and
-the doc-string is contained in `"value"`.
-
-```python
-import json
-
-with open('pymongo.json') as f:
- data = json.load(f)
-```
-
-Here's one record to illustrate the data:
-
-```json
-{
- "key": "pymongo.mongo_client.MongoClient",
- "parent": null,
- "value": "\nClient for a MongoDB instance, a replica set, or a set of mongoses.\n\n",
- "document": "mongo_client.md",
- "res": "pymongo.mongo_client.MongoClient"
-}
-```
-
-**Insert the data into your Atlas cluster**
-
-We can use the SuperDuperDB connection to insert this data
-
-```python
-from superduperdb.db.mongodb.query import Collection
-
-collection = Collection('documents')
-
-db.execute(
- collection.insert_many([
- Document(r) for r in data
- ])
-)
-```
-
-**Define your vector model and vector-index**
-
-Now we have data in our collection we can define the vector-index:
-
-```python
-from superduperdb.container.vector_index import VectorIndex
-from superduperdb.container.listener import Listener
-from superduperdb.ext.numpy.array import array
-from superduperdb.ext.openai.model import OpenAIEmbedding
-
-model = OpenAIEmbedding(model='text-embedding-ada-002')
-
-db.add(
- VectorIndex(
- identifier=f'pymongo-docs',
- indexing_listener=Listener(
- model=model,
- key='value',
- select=Collection('documents').find(),
- predict_kwargs={'max_chunk_size': 1000},
- ),
- )
-)
-```
-
-This command tells the system that we want to:
-
-- search the `"documents"` collection
-- set-up a vector-index on our Atlas cluster, using the text in the `"value"` field
-- use the OpenAI model `"text-embedding-ada-002"` to create vector-embeddings
-
-After issuing this command, SuperDuperDB does these things:
-
-- Configures an MongoDB Atlas knn-index in the `"documents"` collection
-- Saves the `model` object in the SuperDuperDB model store hosted on `gridfs`
-- Applies `model` to all data in the `"documents"` collection, and saves the vectors in the documents
-- Saves the fact that `model` is connected to the `"pymongo-docs"` vector-index
-
-You can confirm that the index has been created and view the index's settings
-in the [Atlas UI](https://cloud.mongodb.com/). It should look like this:
-
-
-
-The nesting of the index signifies the fact that the index created looks
-into the `_outputs..` path, which is where the model's vector outputs are stored
-automatically by SuperDuperDB.
-
-**Use vector-search in a super-duper query**
-
-Now we are ready to use the SuperDuperDB query-API for vector-search.
-You'll see below, that SuperDuperDB handles all logic related to
-converting queries on the fly to vectors under the hood.
-
-```python
-from superduperdb.db.mongodb.query import Collection
-from superduperdb.container.document import Document as D
-from IPython.display import *
-
-query = 'Find data'
-
-result = db.execute(
- Collection('documents')
- .like(D({'value': query}), vector_index='pymongo-docs', n=5)
- .find()
-)
-
-for r in result:
- display(Markdown(f'### `{r["parent"] + "." if r["parent"] else ""}{r["res"]}`'))
- display(Markdown(r['value']))
-```
-
-### Useful Links
-
-- **[Website](https://superduperdb.com/)**
-- **[GitHub](https://github.com/SuperDuperDB/superduperdb)**
-- **[Documentation](https://docs.superduperdb.com/docs/category/get-started)**
-- **[Blog](https://docs.superduperdb.com/blog)**
-- **[Example Use Cases & Apps](https://docs.superduperdb.com/docs/category/use-cases)**
-- **[Slack Community](https://join.slack.com/t/superduperdb/shared_invite/zt-1zuojj0k0-RjAYBs1TDsvEa7yaFGa6QA)**
-- **[LinkedIn](https://www.linkedin.com/company/superduperdb/)**
-- **[Twitter](https://twitter.com/superduperdb)**
-- **[Youtube](https://www.youtube.com/@superduperdb)**
-
-### Contributors are welcome!
-
-SuperDuperDB is open-source and permissively licensed under the [Apache 2.0 license](https://github.com/SuperDuperDB/superduperdb/blob/main/LICENSE). We would like to encourage developers interested in open-source development to contribute in our discussion forums, issue boards and by making their own pull requests. We'll see you on [GitHub](https://github.com/SuperDuperDB/superduperdb)!
-
-### Become a Design Partner!
-
-We are looking for visionary organizations which we can help to identify and implement transformative AI applications for their business and products. We're offering this absolutely for free. If you would like to learn more about this opportunity please reach out to us via email: partnerships@superduperdb.com
diff --git a/docs/hr/blog/2023-10-04-walkthrough-rag-app-atlas.md b/docs/hr/blog/2023-10-04-walkthrough-rag-app-atlas.md
deleted file mode 100644
index 0fa4fc41f3..0000000000
--- a/docs/hr/blog/2023-10-04-walkthrough-rag-app-atlas.md
+++ /dev/null
@@ -1,143 +0,0 @@
-# How to efficiently build AI chat applications for your own documents with MongoDB Atlas
-
-*Despite the huge surge in popularity in building AI applications with LLMs and vector search,
-we haven't seen any walkthroughs boil this down to a super-simple, few-command process.
-With SuperDuperDB together with MongoDB Atlas, it's easier and more flexible than ever before.*
-
-:::info
-We have built and deployed an AI chatbot for questioning technical documentation to showcase how efficiently and flexibly you can build end-to-end Gen-AI applications on top of MongoDB with SuperDuperDB: https://www.question-the-docs.superduperdb.com/
-:::
-
-Implementing a (RAG) chat application like a question-your-documents service can be a tedious and complex process. There are several steps involved in doing this:
-
-
-
-- Serve a model or forward requests to convert text-data in the database to vectors in a vector-database
-- Setting up a vector-index in a vector-database which efficiently finds similar vectors
-- Setting up an endpoint to either run a self hosted LLM or forward requests to a question-answering LLM such as OpenAI
-- Setting up an endpoint to:
- - Convert a question to a vector
- - Find relevant documents to the question using vector-search
- - Send the documents as context to the question-answering LLM
-
-This process can be tedious and complex, involving several pieces of infrastructure, especially
-if developers would like to use other models than those hosted behind OpenAI's API.
-
-What if we told you that with SuperDuperDB together with MongoDB Atlas, these challenges are a thing of the past,
-and can be done more simply than with any other solution available?
-
-Let's dive straight into the solution:
-
-**Connect to MongoDB Atlas with SuperDuperDB**
-
-```python
-from superduperdb.db.base.build import build_datalayer
-from superduperdb import CFG
-import os
-
-ATLAS_URI = "mongodb+srv://@/"
-OPENAI_API_KEY = ""
-
-os.environ["OPENAI_API_KEY"] = OPENAI_API_KEY
-
-CFG.data_backend = ATLAS_URI
-CFG.vector_search = ATLAS_URI
-
-db = build_datalayer()
-```
-
-After connecting to SuperDuperDB, setting up question-your-documents in Python boils down to 2 commands.
-
-**Set up a vector-index**
-
-```python
-from superduperdb.container.vector_index import VectorIndex
-from superduperdb.container.listener import Listener
-from superduperdb.ext.openai.model import OpenAIEmbedding
-
-collection = Collection('documents')
-
-db.add(
- VectorIndex(
- identifier='my-index',
- indexing_listener=Listener(
- model=OpenAIEmbedding(model='text-embedding-ada-002'),
- key='txt',
- select=collection.find(),
- ),
- )
-)
-```
-
-In this code snippet, the model used for creating vectors is `OpenAIEmbedding`. This is completely configurable.
-You can also use:
-
-- CohereAI API
-- Hugging-Face `transformers`
-- `sentence-transformers`
-- Self built models in `torch`
-
-The `Listener` component sets up this model to listen for new data, and compute new vectors as this data comes in.
-
-The `VectorIndex` connects user queries with the computed vectors and the model.
-
-By adding this nested component to `db`, the components are activated and ready to go for vector-search.
-
-**Add a question-answering component**
-
-```python
-from superduperdb.ext.openai.model import OpenAIChatCompletion
-
-chat = OpenAIChatCompletion(
- model='gpt-3.5-turbo',
- prompt=(
- 'Use the following content to answer this question\n'
- 'Do not use any other information you might have learned\n'
- 'Only base your answer on the content provided\n'
- '{context}\n\n'
- 'Here\'s the question:\n'
- ),
-)
-
-db.add(chat)
-```
-
-This command creates and configures an LLM hosted on OpenAI to operate together with MongoDB.
-The prompt can be configured to ingest the context using the `{context}` format variable.
-The results of the vector search are pasted into this format variable.
-
-**Question your documents!**
-
-```python
-input = 'Explain to me the reasons for the change of strategy in the company this year.'
-
-response, context = db.predict(
- 'gpt-3.5-turbo',
- input=input,
- context=collection.like({'txt': input}, vector_index='my-index').find()
-)
-```
-
-This command executes the vector-search query in the `context` parameter. The results of
-this search are added to the prompt to prime the LLM to ground its answer on the documents
-in MongoDB.
-
-### Useful Links
-
-- **[Website](https://superduperdb.com/)**
-- **[GitHub](https://github.com/SuperDuperDB/superduperdb)**
-- **[Documentation](https://docs.superduperdb.com/docs/category/get-started)**
-- **[Blog](https://docs.superduperdb.com/blog)**
-- **[Example Use Cases & Apps](https://docs.superduperdb.com/docs/category/use-cases)**
-- **[Slack Community](https://join.slack.com/t/superduperdb/shared_invite/zt-1zuojj0k0-RjAYBs1TDsvEa7yaFGa6QA)**
-- **[LinkedIn](https://www.linkedin.com/company/superduperdb/)**
-- **[Twitter](https://twitter.com/superduperdb)**
-- **[Youtube](https://www.youtube.com/@superduperdb)**
-
-### Contributors are welcome!
-
-SuperDuperDB is open-source and permissively licensed under the [Apache 2.0 license](https://github.com/SuperDuperDB/superduperdb/blob/main/LICENSE). We would like to encourage developers interested in open-source development to contribute in our discussion forums, issue boards and by making their own pull requests. We'll see you on [GitHub](https://github.com/SuperDuperDB/superduperdb)!
-
-### Become a Design Partner!
-
-We are looking for visionary organizations which we can help to identify and implement transformative AI applications for their business and products. We're offering this absolutely for free. If you would like to learn more about this opportunity please reach out to us via email: partnerships@superduperdb.com
diff --git a/docs/hr/blog/2024-03-11-rag-system-on-duckdb-using-jinaai-and-superduperdb.md b/docs/hr/blog/2024-03-11-rag-system-on-duckdb-using-jinaai-and-superduperdb.md
deleted file mode 100644
index 0e0ee2a1d3..0000000000
--- a/docs/hr/blog/2024-03-11-rag-system-on-duckdb-using-jinaai-and-superduperdb.md
+++ /dev/null
@@ -1,322 +0,0 @@
----
-slug: rag-system-on-duckdb-using-jinaai-and-superduperdb
-title: 'Implementing a RAG System on DuckDB Using Jina AI and SuperDuperDB'
-authors: [anita, fernando]
-tags: [Jina AI, DuckDB, LanceDB, RAG]
----
-
-# Implementing a RAG System on DuckDB Using Jina AI and SuperDuperDB
-
-### Querying your SQL database purely in human language
-
-
-
-Unless you live under a rock, you must have heard the buzzword **“LLMs”**.
-
-It’s the talk around town.
-
-LLM models, as we all know, have so much potential. But they have the issue of hallucinating and a knowledge cut-off.
-
-The need to mitigate these two significant issues when using LLMs has led to the rise of RAGs and the implementation of RAGs in your existing database.
-
-### What is RAG?
-
-
-
-### Let’s paint a picture.
-
-Let’s say you work for an e-commerce company. And you want the non-technical marketing personnel to be able to get updated customer shopping information from the database at will.
-
-**A straightforward way is to build a system that lets them chat with the database in natural human language a.k.a RAG.**
-
-**RAG**, which stands for **Retrieval-Augmented Generation**, is a method used in natural language processing (NLP) to enhance the capabilities of language models. It combines the power of two distinct components: a retriever and a generator. The retriever is used to fetch relevant context or documents from a large corpus of text, and the generator is then used to produce a coherent and contextually relevant output based on both the input query and the retrieved documents.
-
-To build a RAG system, you need two major things
-
-* A database with a vector search functionality
-
-* LLM model(s)
-
-
-
-**One popular and fast OLAP database that fits this use case perfectly is DuckDB.**
-
-[**DuckDB**](https://duckdb.org/) is an **in-process SQL OLAP (Online Analytical Processing)** database management system. It’s designed to be fast and easy to use, focusing on data analytics. Unlike traditional OLTP (Online Transaction Processing) databases optimized for transactional workloads, OLAP databases like DuckDB are optimized for complex queries and aggregations typical in data analysis tasks.
-
-*Find more information about DuckDB [here](https://duckdb.org/docs/)*
-
-At the moment**, DuckDB** does not have native vector-search support.
-
-**SuperduperDB will help with extending this functionality to DuckDB.**
-
-
-[**SuperDuperDB**](https://superduperdb.com/) is a Python framework designed to integrate AI models, APIs, and vector search engines with existing databases directly. It supports hosting your models, streaming inference, and scalable model training/fine-tuning. The framework aims to simplify the process of building, deploying, and managing AI applications without complex pipelines or specialized infrastructure. SuperDuperDB enables the integration of AI and vector search directly with databases, facilitating real-time inference and model training, all while using Python. This makes building and managing AI applications easier without moving data to complex pipelines and specialized vector databases.
-
- **SuperduperDB can enhance the lightweight, fast nature of DuckDB by adding a vector search functionality and AI models to the database in a few simple steps.**
-
-*SuperduperDB also supports other popular databases, like MongoDB, Postgres, Mysql etc. More info about SuperDuperDB data integration can be found [here](https://docs.superduperdb.com/docs/category/data-integrations)*
-
-
-
-The **Jina Embeddings v2** will be used as an embedding model to be used to generate vector embeddings on the existing data.
-
-[**Jina AI**](https://jina.ai/) offers a top-tier embedding model: Jina Embeddings v2, designed to enhance search and retrieval systems with 1 million free tokens for new API keys, facilitating personal and commercial projects without requiring a credit card. This model stands out for its deep integration of cutting-edge academic research and rigorous testing against state-of-the-art (SOTA) models, ensuring exceptional performance. It is the first open-source model to support an 8192-token length, representing entire chapters within a single vector. The model supports multilingual embeddings, including German-English, Chinese-English, and Spanish-English, making it ideal for cross-lingual applications. It also boasts seamless integration capabilities, fully compatible with OpenAI’s API and easily integrating with over ten vector databases and retrieval-augmented generation (RAG) systems, ensuring a smooth and efficient user experience.
-
-
-Jina AI mission is to lead the advancement of multimodal AI through innovative embedding and prompt-based technologies, focusing specifically on areas like natural language processing, image and video analysis, and cross-modal data interaction.
-
-*Find more information about Jina [here](https://jina.ai/).*
-
-In this use case, the retriever will be our vector search, and our generator will be OpenAI’s ChatGPT model **(LLM)**, which will synthesize the output retrieved from the vector search.
-
-The architecture would look something like this.
-
-
-
-The data we will be ingesting into the database will be from [Kaggle](https://www.kaggle.com/datasets/zeesolver/consumer-behavior-and-shopping-habits-dataset?resource=download&select=shopping_behavior_updated.csv), which has 17 columns that consist of customer shopping habit details.
-
-```python
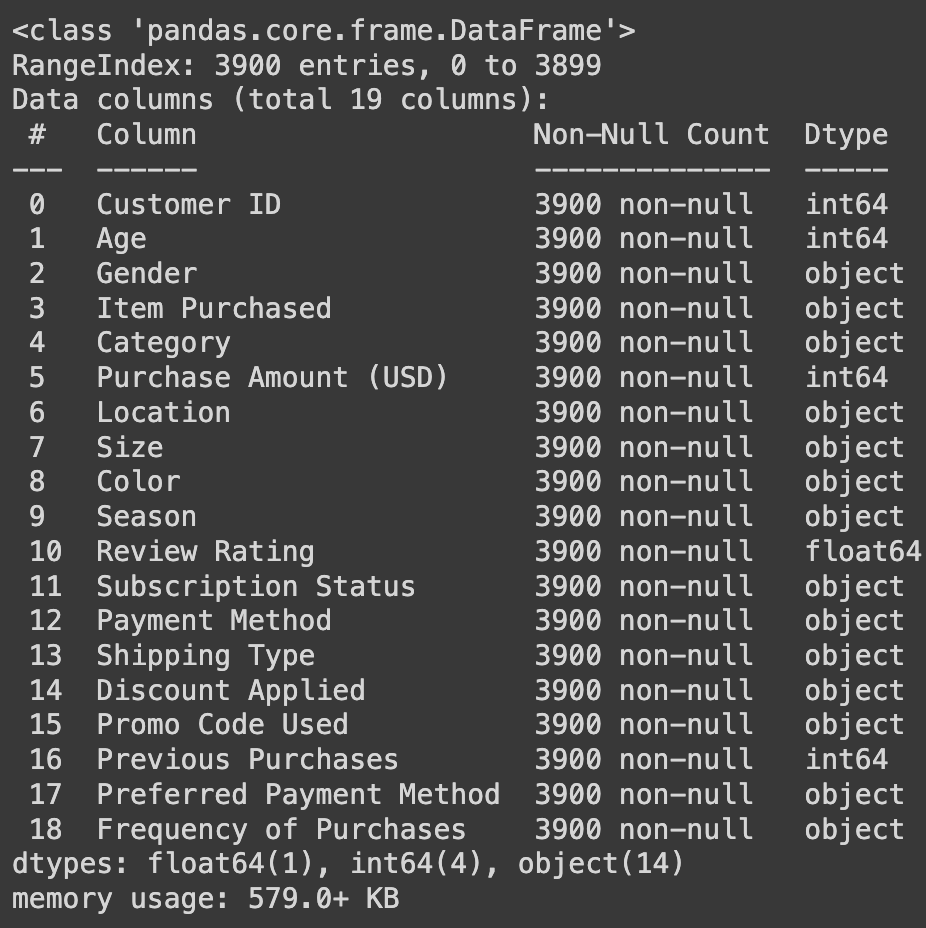
- import pandas as pd
-
- shopping_df = pd.read_csv("shopping_trends.csv")
- shopping_df.info()
-```
-
-
-We will add a column called “Description”, which contains the description of each row.
-
-```python
- def create_description(row):
- description = f"Customer {row['Customer ID']} is a {row['Age']}-year-old {row['Gender']} who purchased a {row['Color']} {row['Item Purchased']} from the {row['Category']} category for ${row['Purchase Amount (USD)']}. "
- description += f"The purchase was made in {row['Season']} from {row['Location']} in size {row['Size']}. "
- description += f"Review rating was {row['Review Rating']}, and the purchase method was {row['Payment Method']} with {row['Shipping Type']} shipping. "
- description += f"Discounts applied: {row['Discount Applied']}, Promo code used: {row['Promo Code Used']}. "
- description += f"Customer has made {row['Previous Purchases']} previous purchases and prefers {row['Preferred Payment Method']} with a purchase frequency of {row['Frequency of Purchases']}. Subscription status: {row['Subscription Status']}."
- return description
-
- # Apply the function to create the description column
- shopping_df['Description'] = shopping_df.apply(create_description, axis=1)
-
- print(shopping_df['Description'][0])
-```
-
-
-
-### Now, let's get started.
-
-Our RAG System implementation would be in 5 steps
-
- 1. Install the necessary libraries and set the environment variable
-
- 2. Connect DuckDB to SuperDuperdb
-
- 3. Define the schema of the data
-
- 4. Add a vector index and an embedding model to the database
-
- 5. Add ChatGPT Model to the database
-
-### Step-by-step:
-
-1. **Install the necessary libraries and set the environment variables.**
-
-*We would be using the Ibis framework to install DuckDB. Ibis is a Python library for data analysis that offers a pandas-like syntax better suited for big data systems. More info about it here [here](https://ibis-project.org/)*
-```python
- ! pip install "ibis-framework[duckdb]"
- ! pip install superduperdb
- ! pip install openai
- ! pip install jina
-
- import os
-
- os.environ['OPENAI_API_KEY'] = 'OPENAI-API'
- os.environ['JINA_API_KEY'] = 'JINA-API'
-```
-
-2. **Connect DuckDB to SuperDuperDB using a DuckDB URI.**
-
-*For this use case, we use Lance as the vector-search backend for DuckDB. We would also define an artifact store path locally and a metadata store path using SQLite.*
-```python
- from superduperdb import superduper
- from superduperdb import CFG
-
- CFG.force_set('cluster.vector_search', 'lance')
- artifact_store = 'filesystem://./my'
- metadata_store ='sqlite:///my.sqlite'
-
- duckdb_uri = 'duckdb://my.ddb'
- db = superduper(duckdb_uri, metadata_store=metadata_store, artifact_store=artifact_store)
-```
-*You can view the configuration this way below.*
-```python
- print(CFG)
-```
-
-
-*However, these configurations are optional. Alternatively, you can skip setting configuration and just connect to SuperDuperDB this way.*
-```python
- duckdb_uri = 'duckdb://my.ddb'
- db = superduper(duckdb_uri)
-
- print(CFG)
-```
-
-
-
-*If none of these configurations are set, it defaults to in-memory vector search. Also, the metadata and artifact store path are None*
-
-3. **Define the table and schema. Add them as well as data to the database**
-
-*Defining the schema involves defining a table name, a unique identifier of the table as the primary key, a schema name, the column names, and their respective datatypes.*
-```python
- from superduperdb.backends.ibis.query import Table
- from superduperdb.backends.ibis.field_types import dtype
- from superduperdb import Schema
-
- shopping_table = Table(
- 'shopping_table', #tablename
- primary_id='Customer ID', #unique identifier
- schema=Schema(
- 'shopping-schema', #schema name
-
-
- )
- )
-
-
- db.add(shopping_table)
-```
-Next, add the Dataframe data to the DB.
-```python
- _ = db.execute(shopping_table.insert(shopping_df))
-```
-You can view the five rows of the table like this.
-```python
- list(db.execute(shopping_table.limit(5)))
-```
-
-
-
-
-
-4. **Add the Jina AI embedding model and the vector index to the database**
-
-*The **“Jina Embeddings v2” **would be used to create the vector embedding on the **“Description” **column on the **“shopping_table”.***
-```python
- from superduperdb.ext.jina import JinaEmbedding
-
- # define the model
- model = JinaEmbedding(identifier='jina-embeddings-v2-base-en')
-```
-*The **Listener function **is used to listen to user queries and convert the queries to vectors automatically using the embedding model. *
-```python
-
- from superduperdb import VectorIndex, Listener
-
- # define the listener
- listener = Listener(model=model,key='Description',select=shopping_table)
-
- # define the vector index
- db.add(VectorIndex(identifier='my-duckdb-index', indexing_listener= listener))
-```
-*More information about Listener can be found[ here](https://docs.superduperdb.com/docs/docs/fundamentals/component_abstraction).*
-
-At this stage, an embedding of all the rows in the description column is automatically populated.
-
-5. **Add the ChatGPT model to the database**.
-
-```python
- from superduperdb.ext.openai import OpenAIChatCompletion
-
- # Define the prompt for the OpenAIChatCompletion model
- prompt = (
- 'Use the following context to answer this question\n'
- 'Do not use any other information you might have learned \n'
- 'Check the context and filter out results that do not match the question'
- 'Only base your answer on the context retrieved\n'
- '{context}\n\n'
- 'Here\'s the question:\n'
- )
-
- # Create an instance of OpenAIChatCompletion with the specified model and prompt
- chat = OpenAIChatCompletion(identifier="chatgpt_model", model='gpt-3.5-turbo', prompt=prompt)
-
- # Add the instance to the database
- db.add(chat)
-
-```
-
-
-### **Excellent, you have built a simple RAG.**
-
-
-
-Let’s test it by creating a simple function that helps to interact with the RAG system.
-```python
- from superduperdb import Document
-
- model_identifier = 'chatgpt_model'
- column_to_vectorize = 'Description'
- vector_index_identifier = 'my-duckdb-index'
-
- def chat_with_database(search_term,
- model_identifier = model_identifier,
- column_to_vectorize = column_to_vectorize,
- vector_index_identifier = vector_index_identifier):
- # Use the SuperDuperDB model to generate a response based on the search term and context
- output, context = db.predict(
- model_name=model_identifier,
- input=search_term,
- context_select=(
- shopping_table
- .like(Document({column_to_vectorize: search_term }), vector_index=vector_index_identifier)
- .limit(5)
- ),
- context_key=column_to_vectorize,
-
- )
- return output.content
-```
-The function above will be the function that would be called as soon as the user or marketing personnel types something related to the database data.
-
-To call the function, use the code below.
-```python
- user_query = 'Find me Customers between age 20 and 28 and with size L'
- print(chat_with_database(user_query)
-```
-
-
-The above shows the results of the query
-
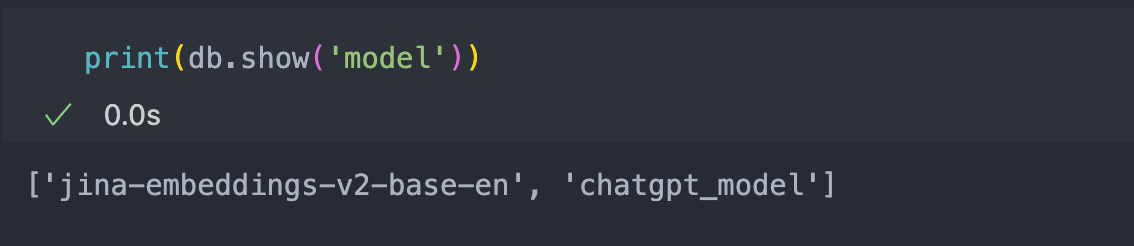
-To check how many models are in your Database, use the code below
-```python
- print(db.show('model'))
-```
-
-
-
-The above shows that two models are simultaneously in the database (the Jina Embeddings v2 and the ChatGPT model).
-
-### Conclusion
-
-Now that you have built and implemented your RAG system, the next step would be to wrap it all in a user interface. And then, you would have a system that helps non-technical chat with your Database purely in human language using Jina AI and SuperDuperDB.
-
-Check out the Jina AI open-source repo and SuperDuperDB open-source repo to stay updated on more functionalities.
-
-
-
-### Useful Links
-
-- **[Website](https://superduperdb.com/)**
-- **[GitHub](https://github.com/SuperDuperDB/superduperdb)**
-- **[Documentation](https://docs.superduperdb.com/docs/category/get-started)**
-- **[Blog](https://docs.superduperdb.com/blog)**
-- **[Example Use Cases & Apps](https://docs.superduperdb.com/docs/category/use-cases)**
-- **[Slack Community](https://join.slack.com/t/superduperdb/shared_invite/zt-1zuojj0k0-RjAYBs1TDsvEa7yaFGa6QA)**
-- **[LinkedIn](https://www.linkedin.com/company/superduperdb/)**
-- **[Twitter](https://twitter.com/superduperdb)**
-- **[Youtube](https://www.youtube.com/@superduperdb)**
-
-### Contributors are welcome!
-
-SuperDuperDB is open-source and permissively licensed under the [Apache 2.0 license](https://github.com/SuperDuperDB/superduperdb/blob/main/LICENSE). We would like to encourage developers interested in open-source development to contribute in our discussion forums, issue boards and by making their own pull requests. We'll see you on [GitHub](https://github.com/SuperDuperDB/superduperdb)!
diff --git a/docs/hr/blog/2024-03-13-nomic-integration.md b/docs/hr/blog/2024-03-13-nomic-integration.md
deleted file mode 100644
index b8b0a34341..0000000000
--- a/docs/hr/blog/2024-03-13-nomic-integration.md
+++ /dev/null
@@ -1,243 +0,0 @@
----
-slug: nomic-integration
-title: 'Integrating Nomic API with MongoDB using SuperDuperDB'
-authors: [anita]
-tags: [Nomic, MongoDB, API]
----
-
-## Integrating Nomic API with MongoDB using SuperDuperDB
-
-
-
-One of the major components of building an RAG system is being able to perform a **vector search** or a **semantic search**. This potentially includes having an **embedding model** and **a database of choice**.
-
-**For this demo, we will be using Nomic’s embedding model and MongoDB in order to accomplish this**
-
-[**Nomic AI**](https://home.nomic.ai/) builds tools to enable anyone to interact with AI scale datasets and models. Nomic [Atlas](https://blog.nomic.ai/posts/atlas.nomic.ai) enables anyone to instantly visualize, structure, and derive insights from millions of unstructured data points. The text embedder, known as Nomic Embed, is the backbone of Nomic Atlas, allowing users to search and explore their data in new ways.
-
-
-
-[**MongoDB**](https://www.mongodb.com/) is a popular open-source NoSQL database that is known for its flexibility, scalability, and performance. Unlike traditional relational databases that store data in tables with fixed schemas, MongoDB uses a document-oriented approach to store data in flexible, JSON-like documents. [**MongoDB Atlas**](https://www.mongodb.com/atlas/database) is a database service that drastically simplifies how people can build AI-enriched applications. It helps reduce complexity by allowing for low-latency deployments worldwide, automated scaling of compute and storage resources, and a unified query API, integrating operational, analytical, and vector search data services.
-
-However, one thing still needs to be solved: how to generate and store embeddings of your existing data on the fly.
-
-
-**SuperDuperDB helps to bridge this gap.**
-
-[**SuperDuperDB**](https://superduperdb.com/) is a Python framework that directly integrates AI models, APIs, and vector search engines with existing databases.
-With SuperDuperDB, one can:
-
-* Seamlessly integrate popular embedding APIs and open-source models with your database, enabling automatic generation of embeddings for your existing data in your database
-
-* Effortlessly manage different embedding models and APIs ( text, images) to suit diverse needs.
-
-* Empower your database to process new queries instantly and create embeddings in real time.
-
-**One bonus point** about using SuperDuperDB is its flexibility in integrating with custom functions.
-
-**We would use this to integrate with the Nomic embedding model.**
-
-
-
-### **Let’s integrate the Nomic embedding model into your MongoDB using SuperDuperDB.**
-
-
-
-**Step 1: Install SuperDuperDB and Nomic**
-```python
- pip install superduperdb
- pip install nomic
-```
-
-
-**Step 2: Set your NOMIC API Key**
-
-Get your Nomic API key from the [Nomic Atlas website](https://atlas.nomic.ai/) and add it as an environment variable
-```python
- import nomic
- NOMIC_API_KEY = ""
- nomic.cli.login(NOMIC_API_KEY)
-```
-
-
-**Step 3: Connect SuperDuperDB to your MongoDB database and define the collection**
-
-*For this demo, we will be using the default MongoDB testing connection. However, this can be switched to a local MongoDB instance, MongoDB with authentication and even MongoDB Atlas URI.*
-```python
- from superduperdb import superduper
- from superduperdb.backends.mongodb import Collection
-
- mongodb_uri = "mongomock://test"
- artifact_store = 'filesystem://./my'
-
-
- db = superduper(mongodb_uri, artifact_store=artifact_store)
-
- my_collection = Collection("documents")
- ```
-
-*Note that*
-
-* *The MongoDB URI can also be either local-hosted or MongoDB Atlas*
-
-* *We also defined an artefact store path locally to store the model and data artefacts*
-
-Next, let’s ingest some sample data directly
-```python
- from superduperdb import Document
-
- data = [
- {
- "title": "Election Results",
- "description": "Detailed analysis of recent election results and their implications."
- },
- {
- "title": "Foreign Relations",
- "description": "Discussion on current diplomatic relations with neighboring countries and global partners."
- },
- {
- "title": "Policy Changes",
- "description": "Overview of proposed policy changes and their potential impact on the population."
- },
- {
- "title": "Championship Game",
- "description": "Recap of the thrilling championship game, including key plays and player performances."
- },
- {
- "title": "Athlete Spotlight",
- "description": "Profile of a prominent athlete, highlighting their achievements and career milestones."
- },
- {
- "title": "Upcoming Tournaments",
- "description": "Preview of upcoming sports tournaments, schedules, and participating teams."
- },
- {
- "title": "COVID-19 Vaccination Drive",
- "description": "Updates on the progress of the COVID-19 vaccination campaign and vaccination centers."
- },
- {
- "title": "Mental Health Awareness",
- "description": "Importance of mental health awareness and tips for maintaining emotional well-being."
- },
- {
- "title": "Healthy Eating Habits",
- "description": "Nutritional advice and guidelines for maintaining a balanced and healthy diet."
- }
- ]
-
-
-
- db.execute(my_collection.insert_many([Document(r) for r in data]))
-```
-*If you already have existing data in your collection, skip the step above*
-
-Next, view the first row of your collection
-```python
- result = db.execute(my_collection.find_one())
- print(result)
-```
-
-
-**Step 4: Define the embedding model in a function wrapper**
-```python
- from superduperdb import Model, vector
- from nomic import embed
-
-
- def generate_embeddings(input:str) -> list[float]:
- """Generate embeddings from Nomic Embedding API.
-
- Args:
- input_text: string input.
- Returns:
- a list of embeddings. Each element corresponds to the each input text.
- """
-
- outputs = embed.text(texts=[input], model='nomic-embed-text-v1')
- return outputs["embeddings"][0]
-
-
- model = Model(identifier='nomic_embedding_model', object=generate_embeddings, encoder=vector(shape=(768,)))
-```
-*Note:*
-
-* *The model identifier is a name to identify the model. It can be any name of choice*
-
-* *The object is to call the custom function created to generate the nomic embeddings*
-
-* *The encoder argument above denotes the shape of the expected embedding output. The expected embedding shape for the NOMIC model is 768*
-
-
-
-Test your model output **on the fly**.
-```python
- model.predict("This is a test")
-```
-
-
-**Step 5: Add the Nomic Embed model and the vector index to the database**
-```python
- from superduperdb import Listener, VectorIndex
-
- collection_field_name = "description"
-
-
- listener = Listener(model=model,key=collection_field_name,select=my_collection.find())
-
- # define the vector index
- db.add(VectorIndex(identifier=f'my-mongodb-{model.identifier}', indexing_listener= listener))
-```
-*The **Listener Class** is used to listen to user queries and convert the queries to vectors automatically using the embedding model. More information about Listener can be found[ here](https://docs.superduperdb.com/docs/docs/fundamentals/component_abstraction).*
-
-At this stage, an embedding of all the rows in the description column is automatically populated.
-
-
-
-### **Congratulations, you are ready to run a vector search!**
-
-Run a simple vector search query with the code below
-
-*For this demo, we would limit the search results to 2. Feel free to increase the limit*
-```python
- user_query = 'sport articles'
- limit_search_results = 2
-
-
- result = db.execute(
- my_collection
- .like(Document({'description': user_query}), vector_index=f'my-mongodb-{model.identifier}', n=limit_search_results)
- .find({}, {'title': 1, 'description': 1, 'score': 1})
- )
-```
-To view the result
-```python
- for r in result:
- print(r.unpack())
-```
-
-
-### Conclusion
-
-Now that you have implemented the vector search functionality, the next step would be to add a chat model to the system to create a complete, simple RAG system. This can also be done with SuperDuperDB.
-
-To explore more, check out our other use cases in the [documentation](https://docs.superduperdb.com/docs/category/use-cases)
-
-**SuperDuperDB also supports vector-supported SQL databases like Postgres and non-vector-supported databases like MySQL and DuckDB.**
-
-Please check the [*documentation*](https://docs.superduperdb.com/docs/category/data-integrations) for more information about its functionality and the range of data integrations it supports.
-
-### Useful Links
-
-- **[Website](https://superduperdb.com/)**
-- **[GitHub](https://github.com/SuperDuperDB/superduperdb)**
-- **[Documentation](https://docs.superduperdb.com/docs/category/get-started)**
-- **[Blog](https://docs.superduperdb.com/blog)**
-- **[Example Use Cases & Apps](https://docs.superduperdb.com/docs/category/use-cases)**
-- **[Slack Community](https://join.slack.com/t/superduperdb/shared_invite/zt-1zuojj0k0-RjAYBs1TDsvEa7yaFGa6QA)**
-- **[LinkedIn](https://www.linkedin.com/company/superduperdb/)**
-- **[Twitter](https://twitter.com/superduperdb)**
-- **[Youtube](https://www.youtube.com/@superduperdb)**
-
-### Contributors are welcome!
-
-SuperDuperDB is open-source and permissively licensed under the [Apache 2.0 license](https://github.com/SuperDuperDB/superduperdb/blob/main/LICENSE). We would like to encourage developers interested in open-source development to contribute in our discussion forums, issue boards and by making their own pull requests. We'll see you on [GitHub](https://github.com/SuperDuperDB/superduperdb)!
diff --git a/docs/hr/blog/authors.yml b/docs/hr/blog/authors.yml
deleted file mode 100644
index 41042e4020..0000000000
--- a/docs/hr/blog/authors.yml
+++ /dev/null
@@ -1,35 +0,0 @@
-blythed:
- name: Duncan Blythe
- title: CTO & Co-founder of SuperDuperDB
- url: https://github.com/blythed
- image_url: https://avatars.githubusercontent.com/u/15139331?v=4
-
-timo:
- name: Timo Hagenow
- title: CEO & Co-founder of SuperDuperDB
- url: https://www.linkedin.com/in/timohagenow/
- image_url: https://media.licdn.com/dms/image/D4E03AQGg35RuVoXOYQ/profile-displayphoto-shrink_800_800/0/1682109861734?e=1715817600&v=beta&t=ntyPTlLo6a2kXWChTp09eanvWGFaYkQcnxtsBqjkq58
-
-nenb:
- name: Nick Byrne
- title: Engineer at SuperDuperDB
- url: https://github.com/nenb
- image_url: https://avatars.githubusercontent.com/u/55434794?v=4
-
-fernando:
- name: Fernando Guerra
- title: Growth at SuperDuperDB
- url: https://www.linkedin.com/in/fernando2guerra/
- image_url: https://avatars.githubusercontent.com/u/9541936?v=4
-
-anita:
- name: Anita Okoh
- title: Data Scientist at SuperDuperDB
- url: https://www.linkedin.com/in/anita-okoh/
- image_url: https://avatars.githubusercontent.com/u/12241062?v=4
-
-rocky:
- name: Md Fazlul Karim
- title: Engineer at SuperDuperDB
- url: https://www.linkedin.com/in/fazlulkarimweb/
- image_url: https://media.licdn.com/dms/image/D4D03AQEx0B8iKeYK7A/profile-displayphoto-shrink_800_800/0/1684785144602?e=1715817600&v=beta&t=oKhK5mUPgBVI6w7y9JH0lD3VgwuDRqVjcP_MhadJJe0
diff --git a/docs/hr/blog/rag-question-answering-components/Bot.jsx b/docs/hr/blog/rag-question-answering-components/Bot.jsx
deleted file mode 100644
index 00b8cf9d0e..0000000000
--- a/docs/hr/blog/rag-question-answering-components/Bot.jsx
+++ /dev/null
@@ -1,85 +0,0 @@
-import React from "react"
-import { useState } from 'react'
-import ReactMarkdown from 'react-markdown'
-import { Prism as SyntaxHighlighter } from 'react-syntax-highlighter';
-import { hopscotch } from 'react-syntax-highlighter/dist/esm/styles/prism';
-
-const MarkdownDisplay = ({responseText}) => {
- return (
-
-
- ) : (
-
- {children}
-
- )
- }
- }}
- />
-
- )
- };
-
- const handleSubmit = async ({ inputText, setResponseText }) => {
- try {
- setResponseText('Awaiting response to "' + inputText + '"...');
- const response = await fetch('https://question-the-docs.fly.dev/documents/query', {
- method: 'POST',
- headers: {
- 'accept': 'application/json',
- 'Content-Type': 'application/json',
- },
- body: JSON.stringify({ "query": inputText, "collection_name": 'superduperdb' }),
- });
- const data = await response.json();
- setResponseText(data.answer);
- } catch (error) {
- console.error('Error:', error);
- }
- };
-
- const Query = ({ inputText, setInputText, setResponseText, question}) => {
-
- const handleInputChange = (event) => {
- setInputText(event.target.value);
- };
-
- const submit = async () => {await handleSubmit({inputText, setResponseText})};
-
- return (
-
-
-
-
- )
- };
-
-
-function Bot({question, answer}) {
- const [responseText, setResponseText] = useState(answer);
- const [inputText, setInputText] = useState('');
-
- return (
- <>
-
-
-
-
-
-
- )
-}
-
-export default Bot
diff --git a/docs/hr/blog/v1/releasingv1.md b/docs/hr/blog/v1/releasingv1.md
deleted file mode 100644
index 6fafeef561..0000000000
--- a/docs/hr/blog/v1/releasingv1.md
+++ /dev/null
@@ -1,157 +0,0 @@
----
-slug: superduperdb-the-open-source-framework-for-bringing-ai-to-your-datastore
-title: 'Integrating AI directly with your databases to eliminate complex MLOps and vector databases'
-authors: [blythed, timo]
-image: /img/super_intro.png
-tags: [Launching Blog, release]
----
-🔮**TL;DR:** *We introduce SuperDuperDB, which has just published its first major v0.1 release. SuperDuperDB is an open-source AI development and deployment framework to seamlessly integrate AI models and APIs with your database. In the following, we will survey the challenges presented by current AI-data integration methods and tools, and how they motivated us in developing SuperDuperDB. We'll then provide an overview of SuperDuperDB, highlighting its core principles, features and existing integrations.*
-
-
-
-### AI adoption is pressing, but difficult
-
-AI is changing every industry and will soon play a central role in software products and services.
-
-Developers today may already choose from a growing number of powerful open-source AI models and APIs. Despite this, there are numerous challenges which face developers when integrating AI with data and bringing machine learning models to production.
-
-### AI and data live in silos separate from one another
-
-Data is crucial for AI, and, most importantly, connecting AI with data is vital for delivering value whether in training models or applying models to application-relevant data. A key problem stems from the disconnect between where data resides (in databases) and the lack of a standard method for AI models to interface with these databases. This results in convoluted MLOps pipelines, involving intricate steps, numerous tools, and specialized vector databases, and contributes to the status quo in which data and AI live in isolated silos.
-
-### Connecting AI with your data to build custom AI is a big challenge
-
-Current solutions require extracting data from the database, and bringing it to AI models. More specifically, extracted data is ingested into complex “MLOps” and “extract-transform-load” (ETL) pipelines that involve various steps, tools, and even specialized “vector-databases” and “feature-stores”. These convoluted pipelines involve sending the data back and forth, from one environment, format, location, or programming language to another.
-
-
-
-In setting up these pipelines, developers are forced to implement a different version of the same task every time they wish to productionize an AI model. Each sub-step of this process may involve multiple sets of installation targets, cloud setups, docker containers, and computational environments. Since every model has its own particular interface and requirements, this leads to huge operational and infrastructural overhead, which multiplies with the number of models, data types, databases, and hardware requirements.
-
-This becomes increasingly difficult when:
-
-- data is constantly updated and changing
-- data resides in multiple locations,
-- data security restrictions disallow the use of AI APIs and require end-to-end self hosting.
-
-Due to this complexity, both individual developers and teams often struggle to put AI-powered applications into production, lacking the required expert knowledge in various domains, and unable to meet the prohibitive costs of deploying and maintaining such pipelines.
-
-### Low-code AI tools and cloud-managed AI often don’t fit the bill
-
-A new wave of AI companies and services offer "few-click" interfaces and "low-code markups" to ease AI-data integration for certain use-cases. However, these fall short of wide applicability. User-interfaces are typically too far removed from the nuts and bolts of AI models to become broadly useful; low-code mark-up languages hide the most important details of AI implementation from the user and render it impossible to override baked in defaults. This means that as soon as an application departs from the most commonly used and documented AI use-cases, developers are left without options for customization.
-
-On the other hand, services of the major cloud providers also make the promise to simplify AI and data integration. These offerings presents two major issues: developers are encouraged to give up full ownership of their stack, leading to costly vendor lock-in. What’s more, these services do little more than repackage traditional MLOps and ETL pipelines, still resulting in substantial developer overhead.
-
-### The problem with vector databases
-
-The popularity of vector-databases, alongside tools such as LangChain and LlamaIndex, has surged in 2023. This boom has been fuelled by the prospect of combining vector-searches with LLMs and the fact that standard databases lack the necessary vector-search functionality, model support, and support for flexible data types required. While these tools allow developers to get started with vector-search quickly, the reality is that, in production, primary data resides in, and will most likely remain in established databases. This means that developers are required to introduce an *additional* specialized database, for this single purpose, to their stacks, leading to data duplication, migration, and management overhead. If data is already stored in an existing, preferred and battle-tested database, then why not simply leave the data there?
-
-# Unifying data and AI
-
-We believe, unifying data and AI in a single environment is the key to facilitating AI adoption. By doing this, the difficulties encountered with MLOps, ETL and vector-databases can be completely avoided.
-
-Specifically, developers need an environment that can work directly with data in the database, enabling flexible integration of AI models, and vector-search, with minimal boilerplate. Ideally this environment should allow developers to connect a model to the database, so that it automatically processes incoming data, making economical use of resources.
-
-# Enter SuperDuperDB
-
-
-SuperDuperDB’s mission is to bring AI to the database, making data migration, data duplication, MLOps, and ETL pipelines things of the past.
-
-SuperDuperDB is a general-purpose AI development and deployment framework for integrating any AI models (including enhanced support for PyTorch, Scikit-Learn, Hugging Face) and AI APIs (including enhanced support for OpenAI, Anthrophic, Cohere) directly with existing databases, including streaming inference, model training, and vector search. SuperDuperDB is **not** a database, it **makes** your existing databases “super-duper”.
-
-```python
-from superduperdb import superduper
-
-# Make your database super-duper!
-db = superduper('mongodb|postgres|duckdb|snowflake|://')
-```
-
-By bringing AI directly to data, solo developers and organizations can avoid the complexity of building and integrating MLOps and ETL pipelines as well as migrating and duplicating data across multiple environments, including specialized vector databases. SuperDuperDB enables the integration of AI with data in the database, storing AI model outputs alongside the source data. These insights and AI outputs are then ready for instant deployment in downstream applications.
-
-SuperDuperDB provides a unified environment for building, shipping, and managing AI applications, including first-class support for:
-
-- Generative AI & LLM-chat applications
-- Vector search
-- Standard machine learning use-cases (classification, segmentation, recommendation, etc.)
-- Highly custom AI use-cases involving application specific, home-grown models.
-
-:::info Support us by leaving a star
-🔮 Please support us by leaving a star the GitHub repo and share it with anyone who could be interested: [https://github.com/SuperDuperDB/superduperdb](https://github.com/SuperDuperDB/superduperdb)
-:::
-
-## Core principles and features of SuperDuperDB
-
-### Open source
-
-We believe AI software should be open-sourced to the community. Truly open-source tools are the only sure way for developers to protect their stacks from vunerable dependencies.
-
-With SuperDuperDB, we are excited to be part of a thriving open-source AI ecosystem. There is a wealth of open-source AI software and models available, including `transformers` from Hugging Face, `llama-2.0` and other LLMs that can compete with OpenAI's closed source models, computer vision models in PyTorch, and a plethora of new open-source tools and models emerging from GitHub.
-
-SuperDuperDB is permissively open-sourced under the Apache-2.0 license, and aims to become a leading standard in adopting and extracting value from this ecosystem.
-
-### **Python first**
-
-Many tools on the AI landscape encourage developers to move away from Python, in favour of specialized user-interfaces, or specific mark-up languages only relevant to the tool in question. This not only ignores the important fact that Python is the programming language of AI research, development and tooling, but the advertised simplicity comes at the great cost of flexibility.
-
-By building SuperDuperDB as an open-source Python package, we are able to provide a simple interface with high-level abstractions for users who wish to get started quickly with AI models, but enabling experts to drill down to any level of implementation detail.
-
-By deploying models directly to the database from Python, there is no overhead incurred by task-switching to other programming languages or environments. Using SuperDuperDB developers may:
-
-- add, leverage and work with any function, program, script or algorithm from the Python ecosystem to enhance workflows and applications.
-- retain full control over the inner workings of models and training configurations
-- combine SuperDuperDB with favoured tooling such as the vastly popular FastAPI. ([See here for an open-source chatbot implementation based on SuperDuperDB and FastAPI](https://github.com/SuperDuperDB/chat-with-your-docs-backend), which showcases how easily SuperDuperDB and the Python ecosystem interact.)
-- interface with their database using SuperDuperDB directly from a Jupyter notebook - the data scientist’s development environment of choice.
-
-### Avoid **complex pipelines**
-
-Arbitrary pipeline builders, as offered in typical MLOps tooling, typically consist of repeated rounds of ETL, with a variety of models and processors. By understanding the patterns which AI developers typically apply, we were able to build a framework which avoids the necessity of pipeline building while leveraging compute in the most efficient way possible.
-
-As a result, SuperDuperDB allows developers to:
-
-- avoid data duplication and migration.
-- avoid additional pre-processing steps, ETL, and boilerplate code.
-- activate models to compute outputs automatically as new data arrives, keeping deployments up-to-date.
-- train AI models on large datasets, utilizing the in-built scalability of SuperDuperDB.
-- set up complex workflows by connecting models and APIs to work together in an interdependent and sequential manner.
-
-### Avoid specialized vector databases
-
-With SuperDuperDB, there is no need to duplicate and migrate data to additional specialized vector databases — your existing database becomes a fully-fledged multi-modal vector-search database, with support for arbitrary data types, and generation of vector embeddings and vector indexes of your data with arbitrary AI models and APIs.
-
-### Support for arbitrary data types
-
-SuperDuperDB supports images, video, and arbitrary data-types which may be defined in Python; this includes efficient use of hybrid database-filesystem storage, allowing developers to make the most effective use of storage modalities and achieve great I/O performance.
-
-### First-class support for generative AI as well as classical machine learning
-
-SuperDuperDB levels the playing field for all AI models, regardless of complexity. Setting up applications such as retrieval-augmented-generation (RAG) chatbots, which combine generative AI and vector search, is as easy as setting up a wide range of industry use-cases involving tabular data, time-series, and more, all of which still hold immense value. Even applications that combine generative AI with classical ML algorithms can be seamlessly integrated into a single workflow.
-
-
-
-# Current Integrations:
-
-### Datastores:
-
-
-
-### AI Frameworks & APIs:
-
-
-
-
-# Use-cases and applications
-
-We have already implemented numerous use-cases and applications, such as LLM RAG chat, forecasting, recommenders, sentiment analysis which you can refer to in the [README of our main repository](https://github.com/SuperDuperDB/superduperdb) and in our [example use cases documentation](https://docs.superduperdb.com/docs/category/use-cases)
-
-
-
-In addition, we already have several impressive applications and use-cases built by the open-source community, which we are excited to present in our dedicated community apps showcase repo: [SuperDuperDB Community Apps](https://github.com/SuperDuperDB/superduper-community-apps).
-
-# Vision, roadmap, and how to get started
-
-After reviewing the use cases, you’ll be ready to build your own AI applications using your own database. For assistance, please refer to our [documentation](https://docs.superduperdb.com/docs/docs/intro) and join our [Slack](https://superduperdb.slack.com/join/shared_invite/zt-1zuojj0k0-RjAYBs1TDsvEa7yaFGa6QA#/shared-invite/email). We would also love to hear about your project and help you to share it with the community.
-
-The current focus of the roadmap is making the deployment of SuperDuperDB absolutely production-ready and to improve optimizations for deployment, compute efficiency and scalability.
-
-:::info Leave a star
-❤️🔥 If you haven’t yet, now is the time to leave a star on GitHub to support the project and share it with your friends and colleagues: https://github.com/SuperDuperDB/superduperdb
-:::
\ No newline at end of file
diff --git a/docs/hr/content/docs/intro.md b/docs/hr/content/docs/intro.md
index 50049fac4e..7b35369966 100644
--- a/docs/hr/content/docs/intro.md
+++ b/docs/hr/content/docs/intro.md
@@ -14,7 +14,7 @@ SuperDuperDB is **not** a database. SuperDuperDB is an open platform unifying da
By integrating AI at the data's source, we aim to make building AI applications easier and more flexible: Not just for use in standard machine learning use-cases like classification, segmentation, recommendation, etc., but also generative AI & LLM-chat, vector search as well as highly custom AI applications and workflows involving ultra-specialized models.
-For more information about SuperDuperDB and why we believe it is much needed, [read this blog post](https://docs.superduperdb.com/blog/superduperdb-the-open-source-framework-for-bringing-ai-to-your-datastore/).
+For more information about SuperDuperDB and why we believe it is much needed, [read this blog post](https://blog.superduperdb.com/superduperdb-the-open-source-framework-for-bringing-ai-to-your-datastore/).

diff --git a/docs/hr/docusaurus.config.js b/docs/hr/docusaurus.config.js
index d3d210830d..926b74beaf 100644
--- a/docs/hr/docusaurus.config.js
+++ b/docs/hr/docusaurus.config.js
@@ -48,7 +48,7 @@ const config = {
indexDocSidebarParentCategories: 0,
// whether to index blog pages
- indexBlog: true,
+ indexBlog: false,
// whether to index static pages
// /404.html is never indexed
@@ -183,13 +183,7 @@ const config = {
editUrl:
'https://github.com/SuperDuperDB/superduperdb/blob/main/docs/hr',
},
- blog: {
- showReadingTime: true,
- // Please change this to your repo
- // Remove this to remove the "edit this page" links.
- editUrl:
- 'https://github.com/SuperDuperDB/superduperdb/blob/main/docs/hr',
- },
+ blog: false,
theme: {
customCss: require.resolve('./src/css/custom.css'),
},
@@ -234,7 +228,12 @@ const config = {
position: 'left',
label: 'Use Cases',
},
- { to: '/blog', label: 'Blog', position: 'left' },
+ {
+ to: 'https://blog.superduperdb.com/',
+ label: 'Blog',
+ position: 'left',
+ target: '_self',
+ },
{
href: 'https://docs.superduperdb.com/apidocs/source/superduperdb.html',
label: 'API',
@@ -279,7 +278,8 @@ const config = {
},
{
label: 'Blog',
- to: '/blog',
+ to: 'https://blog.superduperdb.com/',
+ target: '_self',
},
],
},